22. October 2021
by Nicolai Ommer | 1353 words | ~7 min read
memory performance java storage comparison

We recently had the requirement to store some medium-sized data (like 100 MB to 1 GB) in a file which should then be fully read into the heap by the application on startup. So we analyzed different file formats in terms of size, read/write performance and overall handling and flexibility:
The source code for this comparison can be found on GitHub.
Protobuf serializes entities as messages into a binary representation. There is no standard way to write a large set of messages into a file, but for some languages like Java, there are convenience methods to read and write messages delimited by their size. Compression can be done with data stream compression manually.
Avro is similar to Protobuf, but also has build-in support for writing multiple entities into a file and handles separation itself. It has several compression codecs built-in which can be set per file. Java classes can be generated by Avro based on an Avro schema file and are natively supported by the Avro reader and writer implementations. Alternatively, data can be stored in GenericRecord. Both variants are included in the results below.
Parquet is a columnar data format. It is mainly used inside the Hadoop universe, but is available as a separate library. It still depends on hadoop-common, so the dependency footprint is significantly larger than for all other formats. It supports the schema definition files of Avro, natively supports storing multiple entities and has built-in compression which works on a per-column level, making compression very efficient. The generated Java classes from Avro can be used as well as the GenericRecord. Additionally, Parquet allows to do the (de-)serialization without Avro. The Group class demonstrates this. It is included in the results as well.
SQLite is a well-known self-contained SQL database which is supported by many languages, including Java. It can basically be used by any database framework using JDBC. The whole database with all tables is stored in a single file. For performance comparison, a database with a single table is used and all data is retrieved with a single select.
JSON is not a binary format and obviously not very efficient in terms of file size, but it is interesting to see how it compares with the other formats. Yasson, which is an implementation of JSON-B, is used here. The entities have been written as new-line delimited JSON-stream.
Kryo is an object graph serialization framework. It can serialize Java objects directly, but thus only supports Java and can not be used in other languages.
MicroStream is similar to Kryo. One notable advantage is that it supports immutable data classes (like Lomboks @Value). It writes data into a folder consisting of multiple files, while all other formats write into a single file.
The data format performance was analyzed by generating a random set of data (10.000.000 entries), writing it with each format into a file and reading it back into the heap afterwards. This was additionally done with gzip compression for each format. The generated data contains a fixed amount of random strings (10.000) to make the effect of compression visible and more realistic.
The following metrics were taken for each storage solution:
The file size per format is as follows:
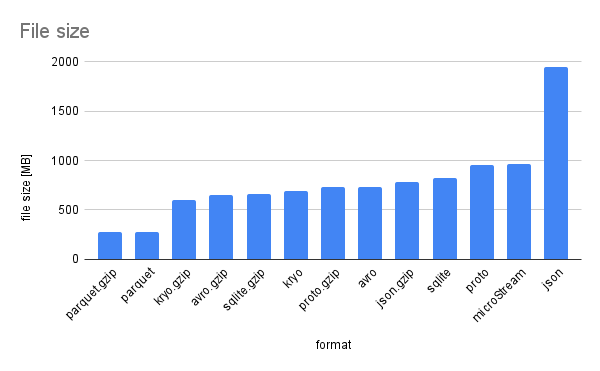
Diagram of file size
Parquet is significantly smaller than the others. This is, because parquet will store duplicate strings much more efficient by de-duplicating the data. The additional gzip compression thus does not reduce the file size much further. The effect is much less significant when there is not so much duplication. JSON is by far the largest one, as expected, but with compression the size is relatively similar to the others.
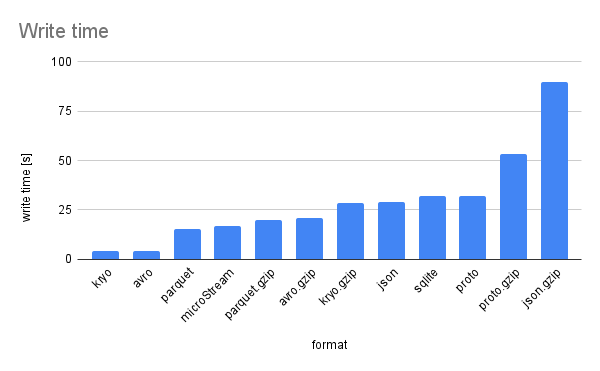
Diagram of write time
Looking at the write times, Avro and Kryo are by far the fastest ones when not compressing data, but compression takes a lot of extra time for all formats. Compressing the SQLite DB even takes several minutes and is thus not shown in the diagram to keep it readable.
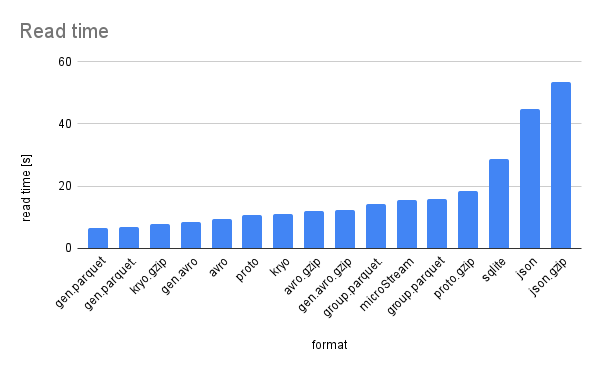
Diagram of read time
When reading the data back, Parquet is leading again, as long as data is directly mapped to the Avro-generated classes. The example group provided by Parquet is very inefficient, both in reading performance and in heap usage. The SQLite DB is slower than the others (except for JSON), as was expected, but it is a full database after all and thus provides other advantages, so it is worth considering it, if the performance overhead is acceptable. Reading and parsing JSON takes 2-3 times more time than the other formats, which is also to be expected.
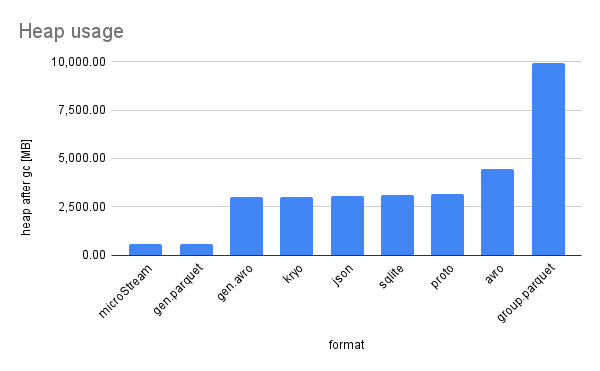
Diagram of heap usage
The heap usage obviously depends on the entity class in the first place. The example group stores data redundantly and thus is twice as large as necessary.
The generic representation of Avro requires a bit more memory and the generated classes for Avro and Protobuf are similar.
The surprise is the data usage of Parquet. Due to the fact that it stores duplicate strings explicitly, it also loads each string only once into the heap.
The other formats always allocate new strings. This is a nice effect of the Parquet format, but could be mitigated by custom string pools or using String#intern().
The full set of result metrics is shown in the following two tables:
| format | write time [s] | file size [MB] |
|---|---|---|
| parquet | 15.326 | 276.40 |
| parquet.gzip | 20.151 | 275.26 |
| avro | 4.219 | 735.77 |
| avro.gzip | 20.776 | 646.44 |
| proto | 32.301 | 955.01 |
| proto.gzip | 53.36 | 735.77 |
| sqlite | 32.296 | 825.00 |
| sqlite.gzip | 523.713 | 665.55 |
| json | 29.169 | 1948.88 |
| json.gzip | 89.793 | 781.17 |
| kryo | 4.218 | 692.82 |
| kryo.gzip | 28.313 | 596.45 |
| microStream | 17.015 | 962.25 |
| format | class | read time [s] | heap usage [MB] |
|---|---|---|---|
| group.parquet | SimpleGroup | 15.686 | 9,965.98 |
| group.parquet.gzip | SimpleGroup | 14.289 | 9,965.99 |
| gen.parquet | SampleDataAvro | 6.495 | 582.86 |
| gen.parquet.gzip | SampleDataAvro | 6.663 | 582.86 |
| avro | Record | 9.356 | 4,446.56 |
| avro.gzip | Record | 11.819 | 4,446.54 |
| gen.avro | SampleDataAvro | 8.494 | 3,014.56 |
| gen.avro.gzip | SampleDataAvro | 12.11 | 3,014.53 |
| proto | SampleDataPb | 10.57 | 3,167.13 |
| proto.gzip | SampleDataPb | 18.374 | 3,167.13 |
| sqlite | SampleDataAvro | 28.578 | 3,112.41 |
| json | SampleDataJson | 44.899 | 3,073.29 |
| json.gzip | SampleDataJson | 53.56 | 3,073.30 |
| kryo | SampleDataKryo | 10.887 | 3,014.62 |
| kryo.gzip | SampleDataKryo | 7.819 | 3,014.62 |
| microStream | SampleDataMicroStream | 15.338 | 576.06 |
The analysis showed some interesting metrics of the different formats. Parquet is a very efficient data format, but comes with a lot of dependencies and thus extra complexity. It is also less common and available tools are sparse. Avro and Protobuf are very similar, but Avro has more features in terms of writing multiple rows and overall showed better performance when working with larger data sets. SQLite, given it is a full SQL database, compares pretty well against the other optimized binary data formats. If you consider reading only parts of the data, consider using such a database to get more flexibility. Kryo is very efficient and especially useful if data is only accessed by a single Java application. The main downside is the absence of a language-independent data schema. MicroStream is similar to Kryo, but significantly slower. On the other hand, it can even (de-)serialize immutable classes.
There is no perfect data format. It always depends on your use-case, but the comparison should help to point you to the right direction for your individual use-case.
In our case, we initially started with Parquet, but then moved to SQLite after the analysis. We wanted to get rid of the large dependency tree that included several dependencies with security issues raised during the OWASP analysis. Additionally, using a database gives us more common and powerful tools for reading and linking the data entities. For these advantages we accepted the larger file size.
Note that all the metrics depend a lot on the actual data, so if you want to find the best data format for your use case, clone the GitHub project and run the benchmark with your own data model.