03. March 2021
by Josef Fuchshuber | 1632 words | ~8 min read
diagnosibility devops observability chaos engineering testing quality

This article shows you the current status of Chaos Engineering rituals, procedures and tooling for the Cloud Native ecosystem. The most important thing up front. Chaos Engineering does not mean creating chaos, it means preventing chaos in IT operations.
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production. 1
Cloud native software solutions have many advantages. However, there is always one negative point: the execution complexity of the platforms and our microservice components increase. Our architectures are made up of many building blocks in the runtime view. With Chaos Engineering (mindset & process) and Chaos Testing (tooling) we can get a grip on this challenge and build more resilient applications and achieve trust in our complex applications.
The human factor is almost more central in Chaos Engineering than our applications. As described above, it is very important that we know the behavior of our cloud native architectures and thus build trust. The second aspect are our ops processes. Is our monitoring and alerting working? Do all on-call colleagues have the knowledge to analyze and fix problems quickly?
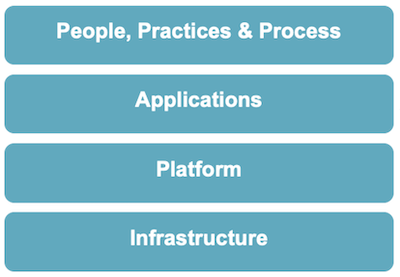
Chaos Engineering Levels
The “what will be tested” with Chaos Engineering can be divided into four categories (from bottom to top):
If you summarize the levels and their questions, you can start as a team with Chaos Engineering for these tasks:
The most lightweight start of Chaos Engineering are Game Days. On Game Day, the complete team (Devs, Ops, QA, Product Owner, …) runs experiments. Tooling is placed in the background first. The primary goal for the entire team is to internalize the Chaos Engineering mindset and to discover and fix anomalies in the process.
Chaos Engineering without observability … is just chaos3

With open eyes into the disaster.
Everyone knows this meme and no one should be as ignorant as our little friend from the comic. You can ignore things deliberately or you can’t ignore them in the beginning because you don’t see them. This is exactly what happens when we don’t have proper monitoring for our application, platform and infrastructure components. For example, from an end-to-end perspective, the RED method4 provides a good view of the state of a microservice architecture. So take care of your monitoring first.
The most common question at the beginning is: In which environment do I run my first experiments? In the beginning, you should always work in the environment closest to production (no mocks, preferably identical cloud infrastructure), but not production. But: Choas Engineering experiments in production are the goal to be, because only there you will find the reality. If you start in a test environment, you must be aware that you have no real customer load during your experiments. You need load generators or acceptance tests to check that the system responds as we assume it will. If these do not yet exist, you will need to build them before your first experiment. Don’t worry, sometimes a small shell script is enough or even our Chaos Testing tooling supports validation.
Now that we have an environment and monitoring, we can start with the first experiments. This image will help us to do so:
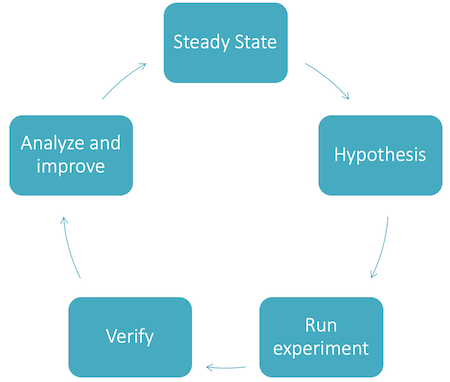
The Phases of Chaos Engineering
The phases of Chaos Engineering can be represented as a cyclic process. A cycle starts and ends in the steady state.
kubectl) or automated via a suitable chaos test tooling.After a successful test, the system must be back in Steady State. This is the case either if the executed action does not change the Steady State (e.g. the cluster detects an anomaly automatically and can heal itself) or a rollback is performed (e.g. database is started up again).
When designing and running the experiment, one of the most important things is always to keep the potential blast radius, i.e., the impact of the error, as minimal as possible and to continuously monitor it. It is helpful to consider in advance how the experiment can be terminated in an emergency and how the Steady State can be restored as quickly as possible. Applications that support canary deployment have a clear advantage here. Because here we can control our work load to the experiment or the normal version of the application.
Any Chaos Engineering experiment requires detailed planning and must be documented in some form. Example:
| Target | Billing Service |
| Experiment | Paypal API is not available |
| Hypothesis | The application automatically detects the outage and no longer offers the payment method to our customers. Customers can still pay by credit card or prepayment. Monitoring detects the failure and automatically creates a Prio-1 Incident. |
| Steady State | All types of payment are available for customers |
| Blast Radius | During the experiment, customers will not be able to pay with Paypal. The alternative payment methods are not affected. |
| Technical information | We simulate the outage of the Paypal API by extremely slowing down the outgoing network traffic of the billing service. We can implement this via the service mesh (sidecar proxies). |
Tip for the design of experiments and hypothesis: Don’t make a hypothesis that you know in advance will break your application and thus is not sustainable! These problems, if they are important, you can address and fix immediately. Only hypothesize about your applications that you believe in. Because that is the point of an experiment.
There is a lot of activity in chaos testing tooling at the moment. New open source and commercial products are constantly being launched. A current overview of the market is provided by the Cloud Native Landscape of the CNCF. There is now a separate Chaos Engineering category5.

Chaos Engineering Tools @ CNCF Landscape
The features of Chaos Engineering tools are manifold:
Unfortunately, there is currently no “one-stop-shop” that will make all teams happy. So each team has to think about their own requirements and pick one or more tools.
Chaos Engineering is not a job description, but a mindset and approach that involves the entire team. The most important thing about Chaos Engineering is that you do it:
Tools will come and go:
To give you a better insight into the Chaos Engineering tools, we introduce some of them. We start with Chaos Toolkit
