20. December 2017
by Harald Störrle | 1015 words | ~5 min read

Background In Part 1 of this article, I have described the motivation and scope of a research project into the perceptions of code quality by different stakeholders. The project has been conducted by a consortium which two scientists from Sweden and I led. The first set of results from that project has been accepted for publication in the ITiCSE’17 proceedings recently1, and that is what I report on in this article. Comics in this blog post courtesy of Geek & Poke.
Code quality is a key issue in software development. One would expect, therefore, that such a basic concept is well understood. In fact, we had expected that introductory courses in computing of higher education programs would communicate this topic clearly and would be the primary source of information for professionals.
It turns out, however, that this is not the case. Actually, different groups of people have very different perceptions of code quality, how they learn about the topic, and what can (and should) be done to improve code quality.
In the study1, we administered questionnaires and conducted structured interviews with 34 students, educators, and professional developers regarding their perceptions of code quality. Participants brought along code from their own experience to discuss and exemplify code quality. From this rich set of data, we so far only analyzed the quantitative part, that is, the study so far is effectively a survey.
Quality was mostly described in terms of indicators that could measure an aspect of code quality. Among these indicators, readability23 was named most frequently by all groups. The next two most frequent mentions were structure and comprehensibility. All other aspects (documentation, dynamic behavior, testability, correctness, and maintainability) were mentioned roughly equally often. There were few differences between different sub populations regarding readability as the single most important aspect, but marked differences about all other aspects. As far as developers are concerned, comprehensibility and correctness follow after readability, while educators name structure, documentation, and dynamic behavior as the most important aspects after readability. For students, structure is almost as important as readability, while correctness is not mentioned at all by students. Similar findings were made when investigating the importance of identifiers in programs4.
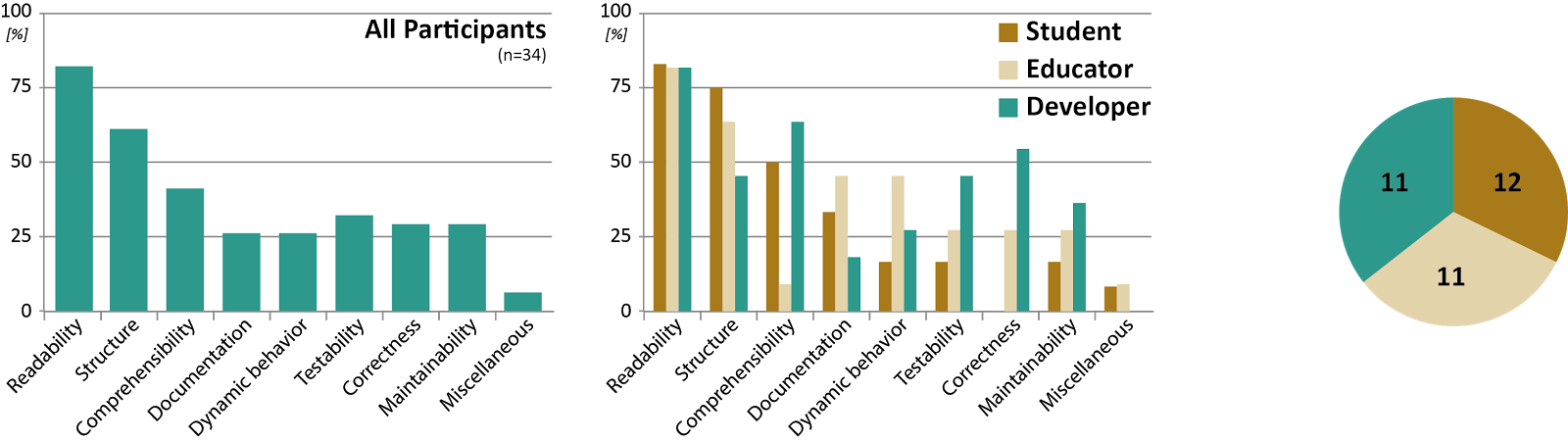
Summing up: developers, educators and students seem to have quite different perceptions of what makes good code quality.
We also looked at the sources people consult to learn about code quality. When asked about the most important sources of information about code quality, both students and developers point to colleagues, while educators refer to textbooks – which is hardly surprising. However, while the internet was mentioned most often as a source by all groups, no group referred to the internet as their dominant first choice. Specifically, developers mentioned the internet only as a secondary point of reference.
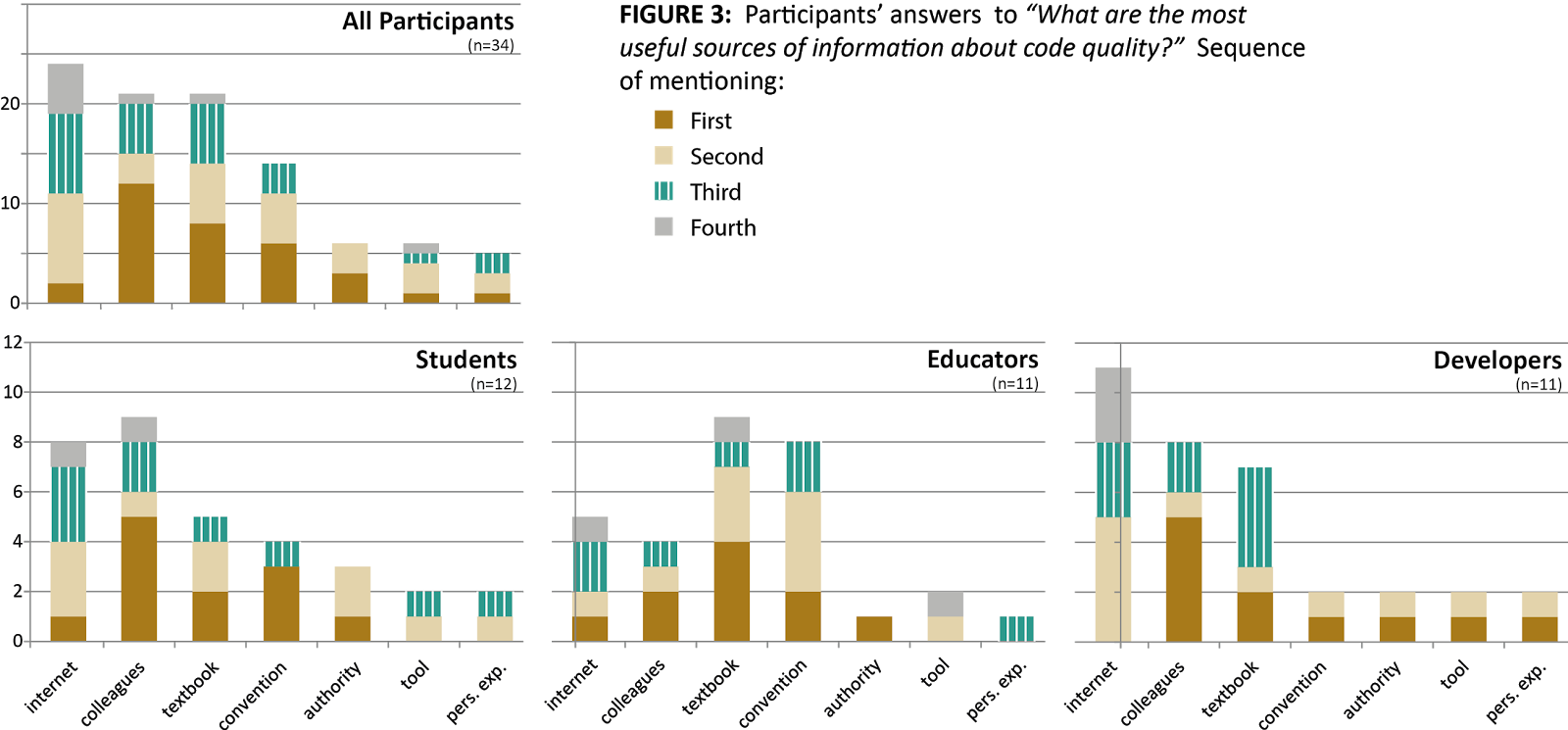
So, while everybody talks about StackOverflow and such, colleagues are really the most used inforamtion “resource” for developers and students. Academics mostly refer to textbooks.
Looking at tool support, we see that educators and students rely heavily on Integrated Development Environments (IDEs), while developers mention continuous integration more frequently. Interestingly though, developers mention static analysis tools as their most frequent primary choice of tools, while both educators and students mention it only as a secondary tool of choice. We conclude from this that education should pay greater emphasis to static analysis tools and continuous integration as tools for code quality assessment.
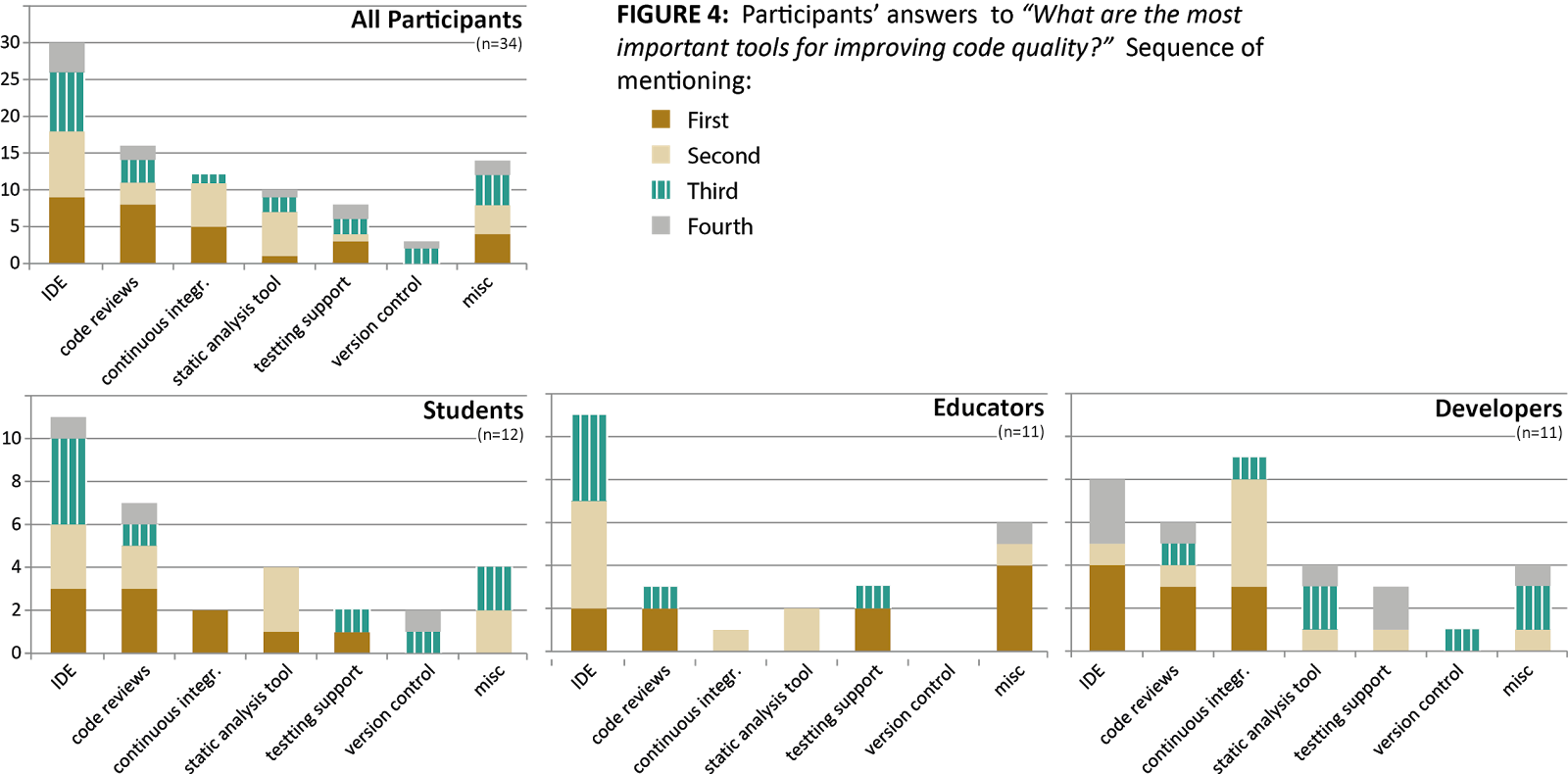
We conclude that static analysis is a topic underappreciated in academic teaching (or learning).
Educators, students, and professional developers have different opinions on what code quality is, and how they form their opinions. Practitioners, it appears, follow an apprenticing model. The internet is an important source of information, but not the first source consulted. Tools are widely used, particularly static analysis tools such as SonarQube5 or the checks built into IDEs.
It is important to note that the data presented here should not be overstretched. It is (so far) only a humble survey after all, and many questions can be asked from a scientific validity point of view (see the source section1 for a more indepth discussion). Particularly, one can complain about the lack of sample representativity, but, frankly, that is virtually impossible anyway6.
As pointed out above, we have yet to analyze the data from the qualitative part of our study. We expect further clues as to which role code quality plays. For an educational setting, we want to explore further what students expect, and which teaching methods are the most promising. This may, in turn, benefit industrial software engineering by better educated junior developers.
From a more personal perspective, the one thing I took away is the degree to which developers and students depend on their colleagues for information. This underscores once more how important communication and learning are in software development. So much for the cliché of the asocial coder in the dark…

J. Börstler, H. Störrle, D. Toll, J. v. Assema, R. Duran, S. Hooshangi, J. Jeuring, H. Keuning, C. Kleiner, B. MacKellar: “I know it when I see it” - Perceptions of Code Quality. In: Proc. ACM Conf. Innovation and Technology in Computer Science Education (ITiCSE), 389, http://dx.doi.org/10.1145/3059009.3081328, ACM 2017 ↩︎ ↩︎ ↩︎
Jürgen Börstler, Michael E. Caspersen, Marie Nordström. “Beauty and the Beast: on the readability of object-oriented example programs.” Software Quality Journal 24.2 (2016): 231-246. ↩︎
Daryl Posnett, Abram Hindle, Premkumar Devanbu. “A simpler model of software readability.” Proc. 8th Working Conf. Mining Software Repositories. ACM, 2011. ↩︎
Dave Binkley, Marcia Davis, Dawn Lawrie, Jonathan I. Maletic, Christopher Morrell, and Bonita Sharif. The impact of identifier style on effort and comprehension. Empirical Software Engineering, 18(2):219–276, 2013 ↩︎
SonarQube – the leading product for continuous code quality. https://www.sonarqube.org/, last accessed 2017-12-0 ↩︎
Robert Kraut, Judith Olson, Mahzarin R. Banaji, Amy Bruckman, Jeffrey Cohen, and Mick Couper. Psychological research online: Report of Board of Scientific Affairs’ Advisory Group on the conduct of research on the Internet. American Psychologist, 59:105–117, 2004. ↩︎