15. June 2016
by Stefan Billet | 1216 words | ~6 min read
java locking memory performance
To provide synchronized data cache access, I discuss three alternatives in Java 8: synchronized() blocks, ReadWriteLock and StampedLock (new in Java 8). I show code snippets and compare the performance impact on a real world application.
Consider the following use case: A data cache that holds key-value pairs and needs to be accessed by several threads concurrently.
One option is to use a synchronized container like ConcurrentHashMap or Collections.synchronizedMap(map). Those have their own considerations, but will not be handled in this article.
In our use case, we want to store arbitrary objects into the cache and retrieve them by Integer keys in the range of 0..n. As memory usage and performance is critical in our application, we decided to use a good, old array instead of a more sophisticated container like a Map.
A naive implementation allowing multi-threaded access without any synchronization can cause subtle, hard to find data inconsistencies:
Thus, we need to provide some form of synchronization.
To fix the problem of memory visibility, Java’s volatile keyword seems to be the perfect fit. However, making an array volatile has not the desired effect because it makes accesssing the array variable atomic, but not accessing the arrays content.
In case the array’s payload is Integer or Long values, you might consider AtomicIntegerArray or AtomicLongArray. But in our case, we want to support arbitrary values, i.e. Objects.
Traditionally, there are two ways in Java to do synchronization: synchronized() blocks and ReadWriteLock. Java 8 provides another alternative called StampedLock. There are propably more exotic ways, but I will focus on these three relatively easy to implement and well understood ways.
For each approach, I will provide a short explanation and a code snippet for the cache’s read and write methods.
synchronized is a Java keyword that can be used to restrict the execution of code blocks or methods to one thread at a time. Using synchronized is straight forward - just make sure to not miss any code that needs to be synchronized. The downside is, you can’t differentiate between read and write access (the other two alternatives will). If one thread enters the synchronized block, everyone else will be locked. On the upside, as a core language feature, it is well optimized in the JVM.
| |
ReadWriteLock is an interface. If I say ReadWriteLock, I mean its only standard library implementation ReentrantReadWriteLock. The basic idea is to have two locks: one for write access and one for read access. While writing locks out everyone else (like synchronized), multiple threads may read concurrently. If there are more readers than writers, this leads to less threads being blocked and therefor better performance.
| |
StampedLock is a new addition in Java 8. It is similiar to ReadWriteLock in that it also has separate read and write locks. The methods used to aquire locks return a “stamp” (long value), that represents a lock state. I like to think of the stamp as the “version” of the data in terms of data visibility. This makes a new locking strategy possible: the “optimistic read”. An optimistic read means to aquire a stamp (but no actual lock), read without locking and afterwards validate the lock, i.e. check if it was ok to read without a lock. If we were too optimistic and it turns out someone else wrote in the meantime, the stamp would be invalid. In this case, we have no choice but to acquire a real read lock and read the value again.
Like ReadWriteLock, StampedLock is efficient if there is more read than write access. It can save a lot overhead to not have to acquire and release locks for every read access. On the other hand, if reading is expensive, reading twice from time to time may also hurt.
| |
All three alternatives are valid choices for our cache use case, because we expect more reads than writes. To find out which is best, I ran a benchmark with our application. The test machine is a Intel Core i7-5820K CPU which has 6 physical cores (12 logical cores with hyper threading). Our application spawns 12 threads that access the cache concurrently. The application is a “loader” that imports data from a database, makes calculations and stores the results into a database. The cache is not under stress 100% of the time. However it is vital enough to show a significant impact on the application’s overall runtime.
As benchmark I executed our application with reduced data. To get a good average, I ran each locking strategy three times. Here are the results:
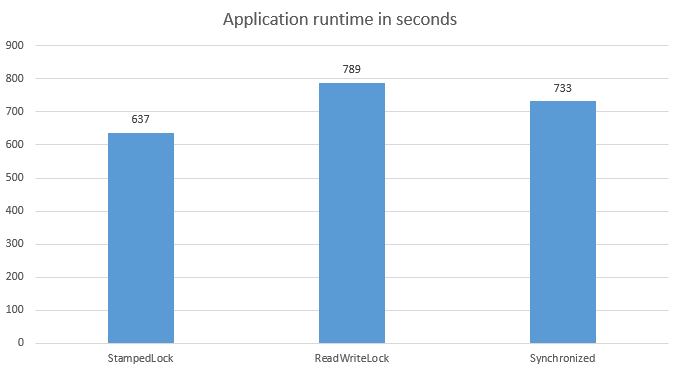
In our use case, StampedLock provides the best performance. While 15% difference to synchronized and 24% difference to ReadWriteLock may not seem much, it is relevant enough to make the difference between making the nightly batch time frame or not (using full data). I want to stress that by no means this means that StampedLock is the best option in all cases. Here is a good article that has more detailed benchmarks for different reader/writer and thread combinations. Nevertheless I believe measuring the actual application is the best approach.