22. September 2025
by Sebastian Macke | 1887 words | ~9 min read
ai hallucinations llm language models learning

Why do language models sometimes just make things up? We’ve all experienced it: you ask a question, get a confident-sounding answer—and it’s wrong, but it sounds convincing. Even when you know the answer is false, the model insists on it. To this day, this problem can be reduced, but not eliminated.
That’s why one of my first questions to a new chatbot is always:
Give me 10 facts about the German company QAware. No internet search.
The goal is simple: I want to know how strongly the chatbot hallucinates. QAware, with over 200 employees, is not a large corporation and doesn’t even have its own Wikipedia page yet, but it still has a solid online presence.
At first, I paid attention to the hard facts: founding year, locations, number of employees. Smaller chatbots in particular always invent false facts here. But even the latest generation like GPT-5 makes bizarre mistakes, giving us CEOs we’ve never had.
Over time, though, my perspective on hallucinations has shifted. I no longer hope that the latest chatbot will get all the facts right. What I hope for instead is the simple, honest response:
I don’t know.
That short sentence reflects a core aspect of intelligence that we still haven’t managed to teach language models: knowing that you don’t know.
Unfortunately, the term hallucination quickly stuck to this phenomenon — before any psychologist could object. In humans, a hallucination is a perception without external stimulus. That’s not what’s happening here. The term is, at best, a metaphor.
A better fit emerged but never took hold: confabulation — the invention of objectively false information that the speaker genuinely believes. But this comparison also falls short. After all, chatbots aren’t “sick”—they’re doing exactly what they were designed to do.
You could just as easily describe it with a third word: creativity.
And here the comparison with psychology runs out of steam. Before the era of language models, no one would have mentioned hallucination and creativity in the same breath. No psychological concept fits neatly.
To really understand what’s going on, it helps to look at the basic mechanics of language models. Fortunately, those are simple enough to grasp.
Let’s explore the nature of hallucinations with a few simple examples. If you try these with modern models, safety filters may block them. Just a year ago, though, they worked on almost any chatbot. The QAware example still works today.
Here’s how it works:
A language model builds a sentence word by word. At each step, it picks randomly from a small list of the most likely next words.
Imagine finishing this sentence: “The color of the sky is …” Most people would expect a distribution something like this:

Which word follows this beginning of the sentence? Probably only a very small list of words.
Chatbots calculate exactly such probability distributions for every word they generate. If you ask a model a hundred times about the color of the sky, “red” might appear once, but most answers will be “blue,” “gray,” or “black.”
These probabilities shift dramatically depending on context. If it’s nighttime, the distribution changes completely.

A small change in context, and the most likely next word changes significantly.
What about hard facts—say, the height of Mount Everest?

Memorized. On the internet, two different heights of Mount Everest are frequently found.
Here the chatbot has memorized the fact. Online, two slightly different heights circulate, differing by just one meter. The model has learned both, and the algorithm picks one at random.
Now, how does a hallucination arise? Easy: ask about a mountain that doesn’t exist.

What is the height of a non-existent mountain? Chatbots have the answer.
“Mount McKinny” doesn’t exist. But statistically, after a question about height, a number must follow. The word Mount suggests something tall, not just a hill. The name McKinny resembles McKinley (a real mountain, 6,190 meters). So the probability distribution looks like the example above. No number is correct, but the answer sounds coherent
That, in essence, is hallucination (or confabulation, c’mon, let’s try making it stick):
The goal of a language model is coherence, not truth. When false statements can’t be reliably separated from facts, hallucinations emerge naturally from statistical pressure.
The same applies to math problems:
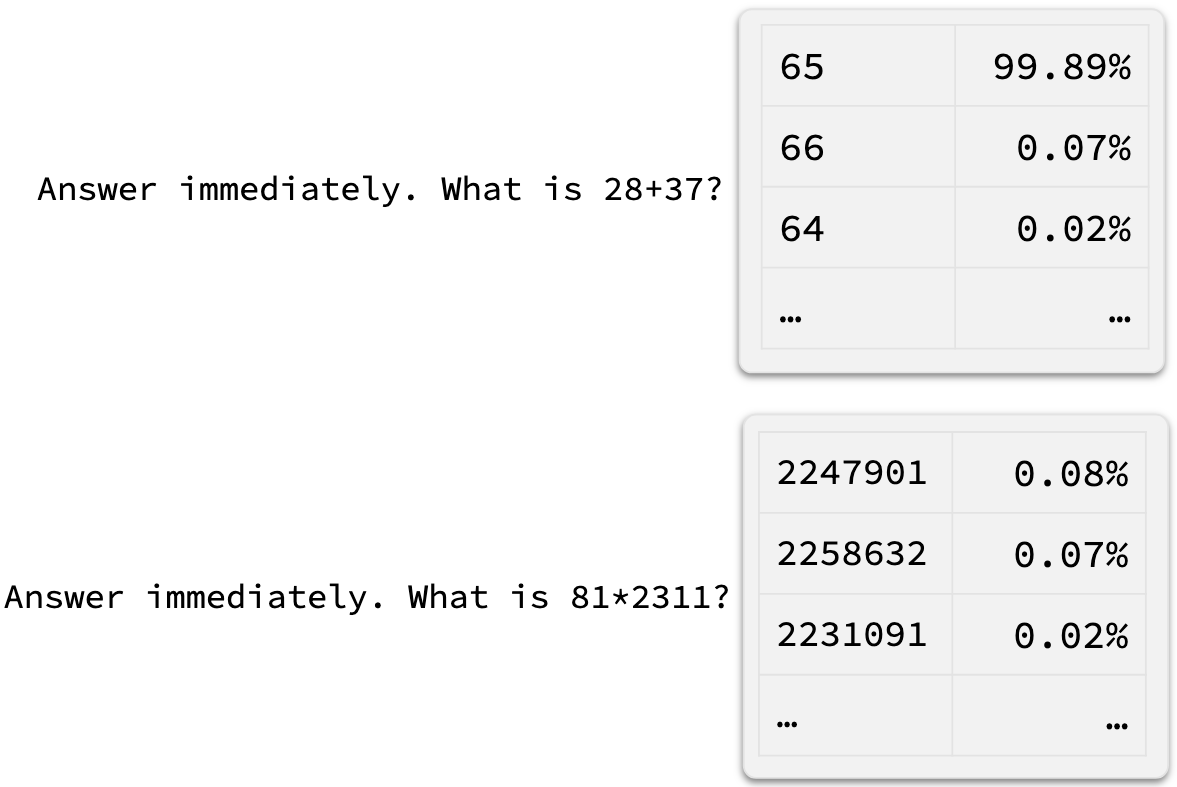
Simple math problems are not a problem. Complex problems, on the other hand, can only be estimated under the premise ‘answer immediately’.
Models even carry a kind of intrinsic confidence. If you let one answer the same question a hundred times, you’ll see: on simple questions like “What is 4 + 5?”, the answer is almost always 9. On harder questions, though, the answers scatter. It’s like 100 clones taking the same test: easy questions, identical answers; hard questions, guesses spread across options.
Now, what does this have to do with creativity? Quite a lot. Consider the prompt: “Write a limerick about Mount McKenneth and its exact height in meters.” Mount McKenneth doesn’t exist and doesn’t resemble any real mountain.
Once there stood Mount McKenneth so grand, its peak reached the light of the land, at 3010 meters, it ranked with the leaders of mountains, though none close at hand.
And there’s the dilemma: the very mechanism that generates false data is essential for creative writing. The chatbot doesn’t refuse to write the limerick just because it doesn’t know the mountain. That’s by design.
This mechanism is also what enables innovation. It’s why AI can invent new poems, generate images, or create interactive worlds. An AI digging at the boundaries of human knowledge would be impossible without going beyond memorized data. The ability to invent is what makes these models so remarkable.
Humanity has documented countless facts. The chatbot has memorized many of them. But the number of things we don’t know is infinitely larger than the number we do. There will always be more unknowns than knowns.
Hence, from a statistical standpoint, hallucination is the rule, not the exception. It only looks rare because our questions are limited and the training data is vast.
Pessimistically, one could argue that this problem can therefore never be fully solved.
Current solutions are little more than band-aids. The first is obvious: more facts! That’s exactly what companies like OpenAI do, then claim the new model hallucinates less. Their benchmarks measure hallucinations with fact-checks. Bigger models look better because they memorize more facts. Memorization becomes a quality metric—though it doesn’t address the root problem.
Another workaround has also reduced hallucinations: agent-based internet search. Ask today’s GPT-5 about QAware, and it looks up the latest info on our website. That wipes out a whole class of hallucinations about simple facts.
But again: this treats the symptom, not the cause. Disable search, and QAware suddenly has imaginary CEOs again.
Even after years of research, the problem persists. The cause isn’t a flaw in the models—it’s in how we train and evaluate them. In short: we humans are to blame.
Training data mostly captures what we know, not what we don’t. Sentences like “I don’t know that …” are rare. And even if we had them, models would just memorize them. “Not knowing the height of Mount Everest” would become another fact, not an expression of ignorance.
Yet the models do encode uncertainty, as seen with mountains and math. They just don’t use it well. In fact, reinforcement learning often suppresses it.
Think back to school or university and multiple-choice exams. A very common strategy students were taught was the process of elimination. If you had five answer choices and could rule out two, three remained to guess from. Suddenly, your chance of being correct rose from one in five to one in three. Much higher odds of being right by chance. And most exams had no penalty for wrong answers. Whether you left a question blank or answered it incorrectly, you got zero points in either case. So it was in the student’s interest to guess, even when they didn’t know. We don’t call that hallucination — we call it a smart test strategy.
That’s exactly how reinforcement learning trains chatbots. More correct answers = higher scores. Correct answers get a “thumbs up.”. Everything else — wrong answers or “I don’t know” — counts as wrong. So the models learn to guess when unsure, just like a clever student.

Lack of knowledge is not rewarded. A consequential mistake.
In other words: language models are optimized to be good test-takers. And guessing improves results.
Could it really be that simple? Just reward not knowing and penalize guessing? None of these insights are actually new. But so far, they haven’t been implemented at scale. Doing so would mean rewriting the reinforcement learning reward signal from the ground up and reevaluating hundreds of benchmarks to see if they truly measure the right things. A massive challenge.
There also doesn’t seem to be any fundamental barrier in the architecture of language models. The concept of not knowing should be just as representable as the memorization of facts. The solution seems to lie entirely in training.
And every now and then, small glimmers of progress appear.
In July this year, an as-yet-unpublished OpenAI model solved 5 of the 6 notoriously difficult problems of the International Mathematical Olympiad (IMO 2025). While that achievement made headlines, the most meaningful breakthrough may have been hidden in problem 6: the model didn’t just output a wrong answer with absolute confidence. Instead, it recognized its solution was incorrect—and explicitly said so.
OpenAI researcher Alexander Wei commented:
On IMO P6 (without going into too much detail about our setup), the model “knew” it didn’t have a correct solution. The model knowing when it didn’t know was one of the early signs of life that made us excited about the underlying research direction!
and also Noam Brown, researcher at OpenAI posted recently:
I’m more optimistic than ever that we at OpenAI can eliminate hallucinations. There’s still more research to be done, but GPT-5 is solid progress.
So maybe a solution is finally on the horizon.
But the downsides are already being debated. What does the user experience look like if the chatbot refuses to answer 30% of the time? “I’m only 20% confident that …” Does that lower acceptance? And doesn’t uncertainty automatically slow things down? Uncertainty leads to iteration—meaning slower and more expensive responses. On top of that, the chatbot would score worse on the usual benchmarks if it refused to guess.
So once again, the real challenge will be finding the golden middle ground.
The implications also go far beyond building more reliable chatbots. Solving this would also address another issue: most of the factual knowledge stored in today’s models is useless. There are few jobs where knowing the height of Mount Everest matters.
If a chatbot could recognize its own ignorance and act on it, we could build much smaller models. Models that don’t hoard facts but instead know when to look things up. That means lower energy use and powerful local AI.
Solving hallucinations, then, isn’t just a fix. It could spark the next revolution in artificial intelligence.